
In discussing the results of my reader survey, I started by writing about the basic demographics and politics of respondents. Then we talked about your likes and dislikes, and the things you’re wrong about.
To wrap up the series, I’m going to talk about birth order effects. I once didn’t think this was something that actually existed. Many years ago I read Judith Rich Harris’ The Nurture Assumption, which seemed to convincingly show that the home environment doesn’t influence how children turn out. If that’s true, then you should be extremely skeptical of any claim that any particular aspect of the home environment, like whether someone’s siblings are older or younger, matters for life outcomes.
But then I read Scott Alexander’s 2018 post on how he found massive birth order effects in his reader survey. His methodology was straightforward. If there were no birth order effects, then whenever there is a reader who grew up in a two-child family, there should be a 50% chance that they were a firstborn. In a three-child family it should be 33.3%, etc. That is nowhere close to what he found.
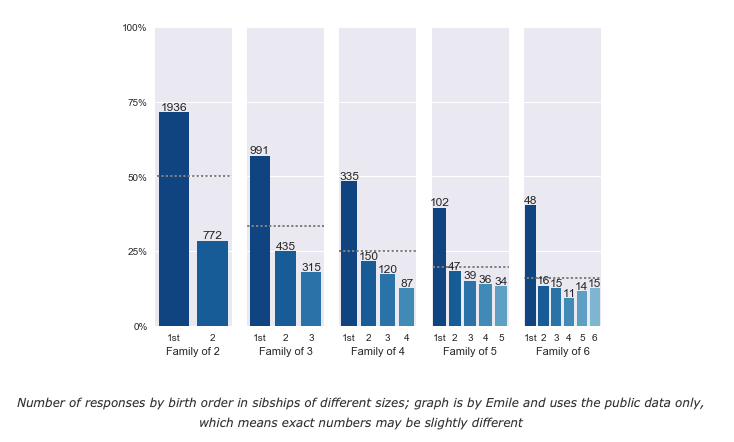
I discovered pretty much the exact same thing among my readers.

These are no small effects. For families of 2, 3, and 4, the number of firstborns exceeds significance at the p < .001 threshold. Even with smaller sample sizes among larger families you still most of the time get significant or borderline significant results. For families of 6 or fewer, you have a pretty consistent finding where the number of firstborns is around 40-50% higher than you would expect by chance.
Here’s a series of graphs where we can see the distribution of where individuals are born based on family size.

So what’s going on? As Scott Alexander implies in his post, I think this reveals not only an issue with the birth-order literature, but with social science more generally. We measure what we can, and to get statistically significant results we need large Ns. To find them, we write papers about the normal range of human experience. Outliers are by definition rare, so we know less about them. If there is a slight advantage in IQ or curiosity or some other trait associated with being a firstborn, then it might be too small for researchers to find remarkable when studying large populations but matter a great deal at the tail end of some distribution, especially if the tools used to measure that trait are flawed. Moreover, the relevant trait that decides whether someone becomes a Hanania appreciator or not might not even be something that psychologists are used to measuring given that they tend to focus on the characteristics on which normal people are most likely to diverge from one another. There’s more to life than the Big Five and IQ, especially among remarkable people.
Similarly, some have pointed out that going to college doesn’t appear to change the political views of students that much. Yet what if what the universities do is take the 2% of students that are most impressionable, turn them into lunatics, and unleash them onto the rest of society? Your data might find no effect, but it shouldn’t lead you to generalize and say the political biases of professors are unimportant. Creating a few activists can have more of an impact on the world than shifting a large portion of the student body slightly to the left.
This reminds me of part of a conversation I had with Bryan Caplan about his book on parenting. Sure, in sizable samples the data indicates that parents don’t really influence how their kids turn out, but what if you are an extremely unusual person? Strangers tell me that they read my writings and it changes how they view the world. Most people don’t have the ability to influence others in that way. Is that an indication that I’m much more likely than the average person to be able to influence my own children, given that I’m more likely to influence strangers? I’d like to think so.
UPDATE, 8/19/22: See this comment for why this is unlikely to be an artifact of the age distribution of the data.
I'd be a major outlier in your study.
I would be the youngest of 5 in my *birth family*, but the only one of the 5 to read Hanania, or read at all. There is a substantial IQ / temperament gap between me and those siblings.
In my adopted family - adopted at a coupla months, I am the oldest of two, where again I'd be the only reader and beneficiary of a sizeable IQ advantage.
If there is a reason (I'm an only child and have no dog in the fight) it might be that older siblings grow up more accustomed to (and liking) having their opinions listened to. Even if the site itself does not provide a way of voicing opinions, the person might still be attracted a "preparation" for opining in other fora.