Epistemology in a World of Fake Data
On not trusting social science and still avoiding epistemological nihilism

If you’re interested in a social scientific question, say whether terrorism works or the relationship between the minimum wage and unemployment, one might think you should “follow the data.” Yet for questions like these we very rarely have randomized experiments to rely on, so social scientists often turn to what seems like the second best thing, which is to look for statistical relationships that remain after you control for various factors that might be important.
For example, a researcher wants to know if being raised by a single parent leads to lower educational achievement. At the same time, he knows that IQ is a potential confounding variable, so he uses a regression to find out whether single parenthood is still associated with bad outcomes once that is controlled for. This might be slightly better than ignoring IQ, but it’s still pretty bad, as the selection effect is still there. People who have kids out of wedlock are distinguished from those who don’t in a thousand different ways, and it’s unlikely you will be able to measure them all. One thing social scientists may do is look at siblings, before and after divorce. The idea would be that siblings at least share the same genes and most of the home environment in common, so if in the same household kids do better when their parents are together you can make an argument that the relationship is causal. This is still not perfect; it may be that more difficult children cause parents to divorce! But I would be interested in reading the second type of study, as I think it would have something to tell us, while the first method where you just control for IQ and various other factors is probably worse than useless, since it misleads you into thinking that you know something that you don’t.
Similarly, researchers have sometimes argued that breastfeeding increases a child’s IQ. When you control for factors like mother’s socioeconomic background and intelligence, however, the relationship plummets. And then when you look at siblings, where one is breastfed and the other isn’t, there is no relationship at all.

Unfortunately, bad research is much more common than good research, since academics who need to publish for careerist reasons have to rely on whatever data is available, and there are many more ways to get data analysis wrong than to get it right.
In many cases, flawed data is worse than no data. Many women have been guilted into breastfeeding when it isn’t the right decision for them. Doctors now even regularly offer to cut the tongues of infants to help them latch on to the breast, which would make sense if undergoing such a procedure could give them 4-5 more IQ points as an adult. Women who have trouble breastfeeding might choose to have fewer children if they believe that providing formula will set their future offspring back in life. There’s a tendency to think flawed data is better than nothing, but I think that’s usually not the case.
Getting a PhD in a social science field made me cynical about most academic research. But two recent papers I think reveal that things are much worse than I thought. They add to what we already know and lead to an important question. Given that we simply cannot, even in theory, rely on data to answer the vast majority of the social science questions involving causal claims we might be interested in, what should we do if we want to form reasonable opinions on social, political, and economic issues? I make the case for seeking out the most important ideas that are well grounded in theoretical reasoning and empirical data and giving them the respect they deserve. In other words, get your priors and heuristics right, instead of chasing the data on every individual issue. Social science is mostly awful, which makes the few glimmers of knowledge we have gained over the centuries that much more valuable.
It’s Worse Than You Thought
One problem with social science research is that it is often difficult to know how generalizable the results of any particular study are. Let’s say that you want to find out whether immigration causes more or less support for economic redistribution. The researcher has to make a countless number of decisions, such as which years to investigate; which measures of immigration to rely on; what measures of support for redistribution to look at; which countries or locations to investigate; and at what level of granularity to consider geographical or political units.
A paper by Breznau et al. (2022) goes one step further and asks what happens if you take many of the most important decisions out of the hands of researchers. Even under such very limited conditions, can quantitative, non-experimental social science help tell us much of anything?
Breznau et al. recruited what ended up being 73 research teams, and gave them data from the International Social Survey Program, which included questions about the appropriate role of government in regulating the economy and redistributing wealth. They also provided them with yearly data on each country’s inflow of migrants, and their stock of immigrants as the percentage of the population. All of this data covered survey waves in the years 1985, 1990, 1996, 2006, and 2016. The teams were to rely on the migration and survey data provided, but were allowed to seek out other sources of information to include in their models. They could, for example, control for year, use dummy variables for things like region, or introduce other independent variables that they thought mattered. Here were the results.
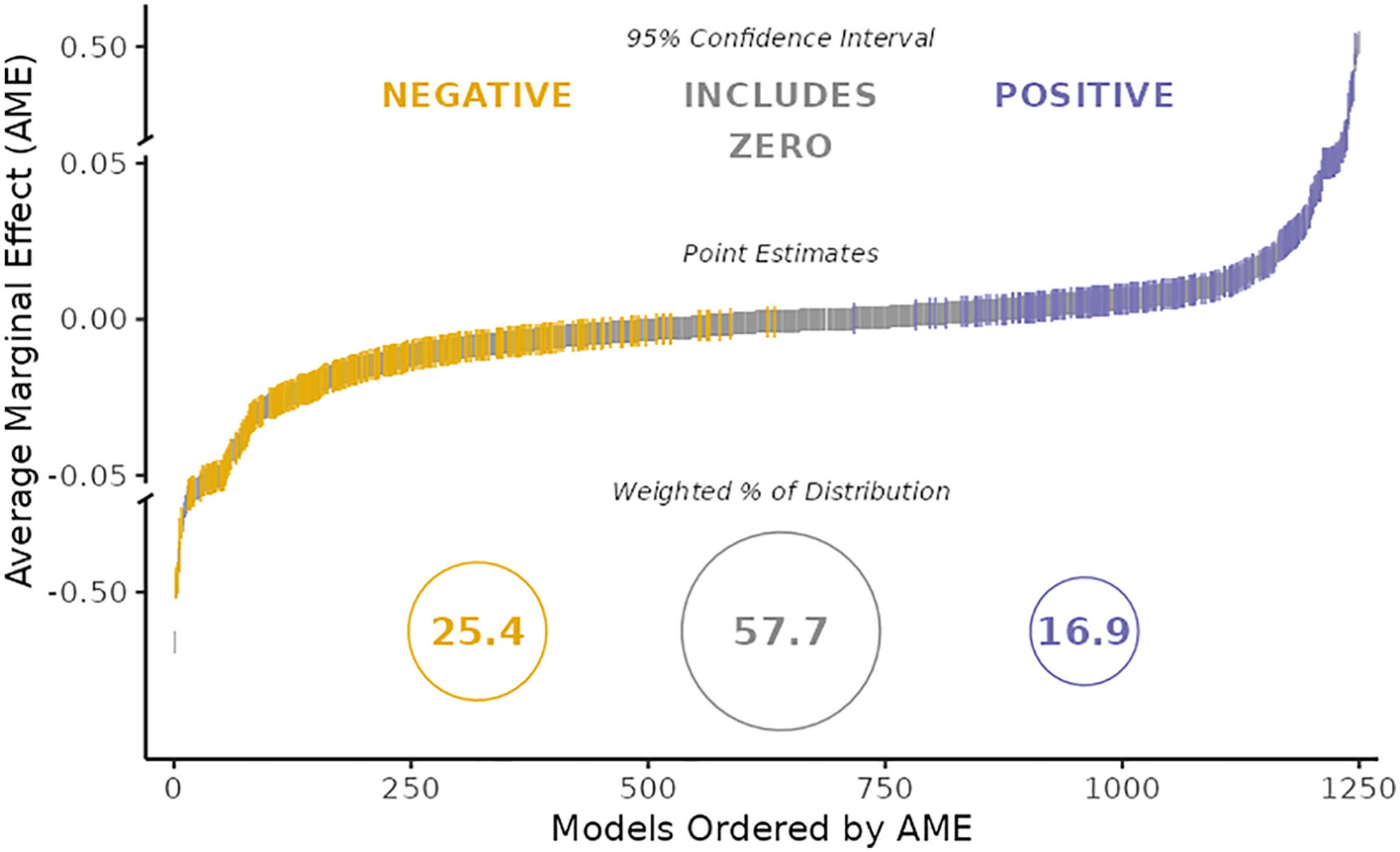
Across all studies, there were 1,261 models used. No two were identical, and the authors identified 166 distinct research choices associated with them. 58% of models found no effect of immigration on attitudes towards redistribution, about 25% found that migrants reduced support, and 17% found a relationship in the opposite direction.
Once again, the research teams were all given the exact same data. In real life, analysts can pick and choose whatever numbers they want. Instead of European nations in 1985, etc., one might look at American states or counties in the 2010s. One may choose to look at voting patterns instead of responses to survey questions. Decisions like this are made well before we get to the point where we can observe what happened in this study, where the researchers had what are usually the most fundamental choices facing a project made for them already. Moreover, the different results of the various teams could not be explained by things like the prior beliefs of researchers or how much expertise they had in statistics. The errors were mostly random and unexplained. Someone might’ve eaten something for lunch that made them want to control for belief in god, for example, while others did not.
So nobody knows the effect of immigration on support for redistributionist policies across European countries in the years considered in Breznau et al. For the sake of argument, let’s pretend that the different teams actually did converge on the same result, say 95% of models found that there was a negative relationship between immigration and support for redistribution. Would that mean we had discovered a law of political science? Not necessarily. The results could potentially be different in other cultural, technological, or economic contexts. A finding from Europe in 1995, even if effectively established, doesn’t necessarily tell you anything about the US in 2030. Yet social scientists distance themselves from historians by claiming to find political or economic laws that are at least somewhat transferrable across contexts. It’s the justification for their entire enterprise. When I was in grad school, I read papers that tried to tell us something about the causes of war today by analyzing what happened in earlier centuries, and I’ve written about the ridiculousness of Graham Allison using a database that starts in the fifteenth century to forecast the future of the US-China relationship. His use of cases is highly questionable and he doesn’t have a large enough sample size to say much of anything, but even if the analysis was done well and actually told us something about the past, the point is it still wouldn’t matter because the world of the 2020s is obviously not Europe before the Industrial Revolution.
If you don’t know anything about statistics and want an intuitive understanding of why the same universe of data can produce different results, picture how a typical argument on this topic you might see on the internet often goes. Someone will say, for example, countries with more migrants show less support for redistribution. Another will say, oh wait, you didn’t include Eastern Europe, which biases the results. The first person might reply ok, but if you look at a longer timeframe you see the finding still holds, and postcommunist states must show a different dynamic. The second one says you shouldn’t rely on surveys, but gather information on how people actually vote in elections. This can go on forever, as there are a limited number of observations and an endless list of potential confounders and ways to splice the data. Statisticians aren’t doing anything magical; when it comes to non-experimental quantitative analysis, they’re basically having this argument with numbers and in Greek letters instead of English. But they can actually make things even more confusing, because unlike wordcels they may also argue about which methods are best.
In graduate school, our methods professor once told the class that knowing complex statistical methods was how you appear smart to your peers and employers. I distinctly remember him going on and saying “What doesn’t sell is truth.” I burst out laughing, which infected others in the class. Clearly, I had much to learn.
Another paper I recently read is yet to be published and was written by Douglas Campbell, who I work with at Insight Prediction, and six other co-authors. Looking at 8 papers published in the American Economic Review from 2013 and 9 from 2022 or 2023, they find just under half of published results aren’t robust, meaning you can get a different outcome by doing things like adding control variables or slightly tweaking the model. This is despite the authors not questioning anything about the way that the original study was done. If there were problems with the original identification strategies, then social science looks much worse. As with the research teams in Breznau et al., in each case Campbell and his co-authors took the questions being investigated and the underlying data as given. It should be noted that economics is the most rigorous of the social sciences, and AER is the top journal in that field. If you can’t trust the research there, you can’t trust anything. The fact that about half the findings were robust might be seen as a reason to be optimistic, but that should nonetheless be treated as a ceiling for how much social science should be trusted, not a floor.
In one particularly funny example, Campbell and his co-authors analyze one paper finding that speakers of languages that do not differentiate the past from the future have higher savings rates. But for reasons that are never explained, South Korea is not included, which would go against that theory. That ridiculous paper currently has 931 citations. This isn’t the exception in quantitative research, and it’s not a case of a few bad apples. The entire system and its epistemological assumptions are rotten to the core. Most quantitative data should be completely discarded.
I see the career of Peter Turchin as basically a reductio ad absurdum of what happens when you have too much faith in statistical modelling. He’s the data equivalent of those postmodern philosophers talking about quantum gayness or whatever, but while all smart people laugh at the latter, I still see Turchin cited by writers who should know better.
The Path to Good Epistemology
None of this means that we should all stop talking about social and policy issues. But we have to be careful about what we’re doing here. “Just trust the data” will not work, as it’s mostly garbage. Something must replace a blind faith in what studies say.
First, I would suggest giving greater weight to social science results that use sound methodology. Saying that most social science is fake means that the few exceptions to this rule, and they do exist, become much more important. I consider behavioral genetics a step above practically everything else in the social sciences, because when you control for genes, in a twin or adoption design, you’re basically taking care of most selection effects. As mentioned above, sibling design studies are also potentially useful. Experiments are of course the best kind of science. Even though there’s been a replication crisis in this sort of work, the type of problems that have been identified are at least theoretically fixable, while the issues in standard quantitative research discussed above are not. Unfortunately, experiments are often expensive and only address narrow questions. Nonetheless, don’t just go looking for the “best” empirical data out there, because the best will often be inadequate.
To go back to the question of whether immigration reduces support for the welfare state, I’ve previously argued that it has in the American context. Noah Carl responded by using cross-national data relevant to the question, to which I replied that he missed my point, as I would argue that there’s no way to predict what the political impacts of immigration will be twenty or thirty years down the line. I believe the best explanation of why America has had a smaller welfare state than European nations has something to do with our diversity, given the close relationship between hostility to political correctness and believing in limited government among the white majority, but I don’t think that this data-informed historical analysis necessarily tells us much about other cultural contexts or what will be true in future decades. In cases where the data can’t really tell us anything, I prefer to just welcome migrants due to the positive first order effects that they bring. We can figure out the political impacts later because we have no idea what they will eventually be.
This leads to the second point about developing a sound epistemology, which is to take big, important facts seriously. A good example of not doing this is Yglesias “following the data” to argue that raising the minimum wage would be a good thing to do because while it may or may not increase unemployment, it would have progressive distributional effects. For this conclusion, he points to Congressional Budget Office estimates, which rely quite a bit on assumptions derived from non-experimental quantitative data, which, as we’ve already discussed, would not necessarily be predictive of future effects even if we could trust estimates about the past.
On issues like the minimum wage, most people who claim to be relying on data are defaulting to their ideological priors, and I think that we would be better off more explicitly discussing what those priors are. In my case, I trust markets and don’t trust any form of government planning, and most of my economic opinions flow from that simple basis. This goes against social desirability bias, as it generally sounds better to come across as an open-minded analyst who goes wherever the data leads rather than an ideologue who has made up his mind before looking at the evidence. However, when the data is inadequate to address what one needs to know to make sensible predictions about the effects of policies, our priors are really all we have. I’m not trying to box anyone into a purely libertarian position. If you want to redistribute wealth, just do so directly, rather than trying to mess with the labor market and thinking you can predict what the consequences of doing so will be. One subcategory of big, important facts covers correlations that are strong and involve sensible causal mechanisms, which means they can be used to assume causation. This is partly how we know that vaccines are good and smoking is bad.
During covid, a lot of people became aware that official science was in a bad state, as experts in public health seemed to come up with new data on a whim to fit with whatever the current political line required. Scientists said that people needed to stay home, that is, until they went out to protest racism, since racism is a public health issue. Admittedly, it’s at least theoretically possible that the effect of racism is so bad it’s worth spreading covid to fight it, but the idea that these people were doing any kind of cost-benefit analysis rather than blowing with the political winds is absurd. The important thing to realize is that this was just a particularly ridiculous case of something that is actually the norm in social science, where you can usually cook up whatever data you want to fit with current ideological preferences.
Finally, telling someone to have the right priors is just another way of saying that common sense is seriously underrated. Recently, Ruxandra Teslo asked on Twitter whether there was good evidence that university education has a positive causal impact on life outcomes. Many of the studies cited in response had all the problems one would recognize from some of the papers discussed above. This question goes back to the debate over whether education actually does good in the world, or all the supposed positive impacts are based in selection effects, which would imply that more education is a negative sum proposition in developed societies.
Here, I believe we have to rely on logic and experience. I’ve taught university students, but the idea that I was making them smarter or causing them to live longer by helping them understand concepts they would soon forget (I’ve forgotten many of them myself) is self-evidently absurd. Regarding things like longer training in medical or law school, there is simply no reason to believe that the impact on performance is worth it given that our systems of credentialism were not arrived at through market forces or ever even justified through experimental methods. Sure, people may cite data against credentialism, but the best reason to be against it is common sense. I’ve known academics who actually believe in the causal powers of education even beyond the high school level, and to start out with that prior requires such a lack of wisdom and understanding of the world around you that I wouldn’t trust you to be able to reasonably gather and interpret relevant statistics on this question or any other.
In the end, we’d all be better off with less data analysis, taking the few solid cases of data analysis more seriously, and openly debating the ideological priors we’re bringing to the table. The seduction of outsourcing the outcomes of major debates to data, no matter how questionable, lies in the fact that it seems like an objective arbiter. Moreover, the focus on mindless statistical analysis provides jobs to academics and think tankers, who can always find new numbers to crunch but might not have anything original or relevant to say on important questions. This system leads to a marketplace of ideas in which the ideological preferences of scholars are given a veneer of scientific certainty they don’t deserve.
Academia rightfully gets a lot of heat for this, but there are also egregious examples in the corporate world. I'm not talking about the DEI staff either. Elite overproduction means that the average Fortune 500 company has thousands of high IQ staff who do nothing but analytical masterbation and whatever other tasks exist solely because their company operates at a needlessly complex level. This is the equivalent of naval gazing in the academic world.
“In cases where the data can’t really tell us anything, I prefer to just welcome migrants due to the positive first order effects that they bring. We can figure out the political impacts later because we have no idea what they will eventually be.”
The economist Steve Landsburg, in his popular book _The Armchair Economist_, argues that one big reason that taxes are bad is that people don’t like to pay them. He doesn’t offer any data to explain the obvious. So, while it may be true that immigrants create positive first order effects, one way we know that mass non-white immigration is bad is that people don’t like alien phenotypes. One way we know this is true because pro-immigration advocates are constantly preaching about the alleged badness of rejecting alien phenotypes/racism. But because so many pro-immigration folks (even those who are “based”) have internalized the PC anti-racist ideology, they (including so-called economists) simply dismiss the massive externalities staring them in the face. In other words, mass non-white immigration doesn’t have to lead to “balkanization” to be bad (although the peaceful existence of racial enclaves is a kind of balkanization).
In addition, while often decrying Trump’s violation of democratic norms, pro-immigration folks ignore the preferences of the masses and endorse state-managed mass immigration that ignores the de jure ownership of the streets, roads, etc. by the natives. In this attitude, they are akin to progressive puritans banning and/or taxing cigarettes because they know better than the masses. Again, it is not “collectivism” or a violation of classical liberal tenets to defend de jure ownership. If you are a libertarian, the answer to “Who owns the streets?” can’t be the whole world—that would be communism. Therefore, respect for property rights means immigration by invitation only, not simply a border crossing. (And while decrying the “collectivism” of de jure ownership, some of these so-called libertarians have no trouble defending Israel and its bombing campaign against Gaza.)
The reality is that if we had had private ownership of streets, etc. all along, mass non-white immigration would have been impossible on the levels it exists today. Instead, the anti-racists prefer to violate de jure property to achieve their policy preferences—preferences primarily built upon an anti-racist ideology, not just economics (although economics that ignores externalities is also bad).